Getting the Most from Codex Subscriptions
· 2 min read
· DeanoC
🎛️ Getting the Most from Codex Subscriptions

If you're juggling multiple Codex tiers and weekly limits, the real trick isn’t picking the “best” model.
It’s orchestrating them.
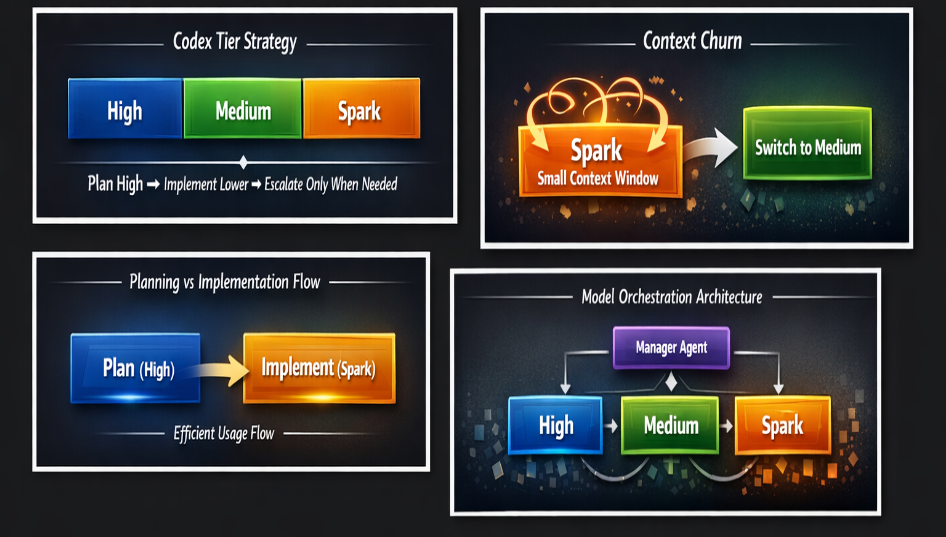
1️⃣ Spark Is Brilliant… Until It Isn’t
gpt-5.3-codex-spark is fantastic for clearly defined implementation tasks.
But it has a smaller context window. When tasks grow, you may see repetition and churn.
When that starts happening:
Switch to
gpt-5.3-codex (medium) to finish.
Often it resolves in minutes what Spark churned on for hours.
2️⃣ Plan High, Implement Lower
When usage is tight:
gpt-5.3-codex (high)gpt-5.3-codex-sparkIf Spark loops, escalate to medium.
3️⃣ Abuse Code Review (Strategically)
Code review often uses a separate budget.
Use this loop:
Implement → Review → Fix → Review → Fix
This is extremely efficient for squeezing weekly limits.
4️⃣ Spark XHigh vs High
Spark XHigh doesn’t dramatically outperform High when the issue is context churn.
The bottleneck is memory pressure, not thinking depth.
5️⃣ Plan One Tier Up, Code One Tier Down
Default pattern:
Plan with High
Code with Medium
Escalate only when stuck.
6️⃣ Two Silicon Heads Are Better Than One
If you have access to another model:
Use it to critique architecture.
Sometimes a second model surfaces blind spots instantly.